


一款中國AI模型,24小時內橫掃美國App Store榜單,連ChatGPT都被擠下神壇。DeepSeek的橫空出世,不僅讓矽谷巨頭Meta緊急組建研究小組,更證明了美國「制裁」或許正在催生中國在AI領域的「彎道超車」。

中國人工智能公司深度求索開發大模型DeepSeek-R1。AP圖片
這兩天,中國人工智能公司深度求索開發的大模型DeepSeek-R1一經推出,憑借其「物美價廉」的特性在海外開發者社區中引發了轟動。
截至北京時間1月27日早,DeepSeek在美區蘋果App Store免費榜上已經排在第一位,力壓此前霸榜的ChatGPT。而就在昨天早上,DeepSeek還沒有擠進榜單前五,顯示出過去24小時發酵速度之快。在國區蘋果App Store免費榜,DeepSeek也已登頂。

DeepSeek已在蘋果App Store國區和美區免費榜登頂。
據美國《華爾街日報》當地時間1月26日報道,DeepSeek-R1的出色表現已經給美國科技行業留下深刻印象,從業者紛紛稱贊深度求索的工作取得了重大突破。OpenAI公司前高管扎克·卡斯(Zack Kass)直言,美國試圖通過制裁限制中國的AI發展,但資源的限制反而激發了中國科研人員的創造力。
深度求索在1月20日發佈了DeepSeek-R1模型,該公司表示,DeepSeek-R1在後訓練階段大規模使用了強化學習技術,在僅有極少標注數據的情況,極大提升了模型推理能力。在數學、代碼、自然語言推理等任務上,其性能比肩美國OpenAI o1正式版。
為促進技術社區的充分交流與創新協作,深度求索還公開了DeepSeek-R1訓練技術。
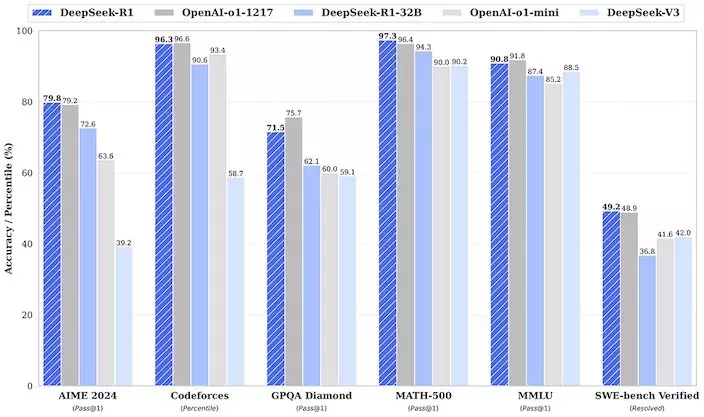
DeepSeek-R1、OpenAI-o1-1217和DeepSeek-V3的性能比較。DeepSeek微信公眾號
一些第三方測試結果也顯示,DeepSeek-R1的表現足以匹敵美國頂尖AI模型。美國加州大學伯克利分校研究人員設立的聊天機器人競技場(Chatbot Arena)平台上,DeepSeek-R1和去年12月發佈的DeepSeek-V3的性能表現均位列前十。
不僅如此,DeepSeek的開發成本和使用的算力規模都遠低於美國頂尖AI公司。先前發佈的DeepSeek-V3在僅使用2048顆英偉達H800 GPU的情況下,完成了6710億參數模型的訓練,成本約為560萬美元,這遠低於其他頂級模型的訓練成本。美媒指出,H800的算力要弱於英偉達H100等芯片,美國限制對華出口此類高性能芯片。
《華爾街日報》提到,作為對比,美國AI企業、Claude模型開發商Anthropic首席執行官達里奧·阿莫代伊(Dario Amodei)去年曾透露,該公司構建模型的成本約為1億至10億美元。
與其他一些頂尖大模型不同,DeepSeek-R1沒有使用傳統的監督微調(SFT)方法,而是專注於強化學習(RL),這意味著該模型跳過了使用人工標準數據訓練的「模仿」環節。
英偉達高級研究科學家范麟熙(Jim Fan)稱贊DeepSeek取得了突破,他在社交平台X上發文稱,DeepSeek-R1完全由強化學習驅動,「這讓人想起了AlphaZero,從零開始學習圍棋、將棋和國際象棋,而不是先模仿人類大師的動作。這是論文中最重要的收穫。」
DeepSeek-R1的表現引起美國科技行業的高度關注。
矽谷風險投資家馬克·安德森(Marc Andreessen)表示:「DeepSeek-R1是我見過的最令人驚嘆,最令人印象深刻的突破之一。」
舊金山AI硬件公司Positron的聯合創始人巴雷特·伍德塞德(Barrett Woodside)表示,最近他和同事一直在討論DeepSeek的開源模型,「這太酷了。」
一些美國企業也開始在工作中使用DeepSeek。
AP圖片
矽谷一家創業公司的聯合創始人安東尼·普奧(Anthony Poo)告訴《華爾街日報》,他們原先使用Claude模型預測財務回報,但現在已轉向DeepSeek,兩者性能相似,使用DeepSeek的成本僅為Claude的四分之一。
普奧說:「OpenAI的模型有著極佳的性能,但我們不想為我們不需要的能力付費。」
DeepSeek發佈後不久,Meta首席執行官朱克伯格就宣佈,Meta計劃在2025年投入超600億美元,加大對人工智能的投入。扎克伯格本人一直是開源模型的倡導者。
1月27日,據Information網站,臉書母公司Meta成立了四個專門研究小組來研究DeepSeek的工作原理,並基於此來改進旗下大模型Llama。
其中兩個小組正在試圖瞭解幻方量化如何降低訓練和運行DeepSeek的成本;第三個研究小組則正在研究幻方量化可能使用了哪些數據來訓練其模型;第四個小組正在考慮基於DeepSeek模型屬性重構Meta模型的新技術。
OpenAI、Meta和其他頂級人工智能團隊的開發人員一直在仔細研究DeepSeek模型,並試圖搞清楚其為何能夠比一些美國製造的模型更便宜、更高效地運行。
OpenAI科學家Noam Brown上周在社交媒體上表示:「DeepSeek表明你可以用相對較少的計算獲得非常強大的AI模型。」
數日前,就有Meta的工程師們在匿名社交平台TeamBlind上吐露心聲,表示DeepSeek所研發的AI模型為其帶來了巨大壓力。
近年來,美國在芯片等領域對中國實施出口限制,試圖打壓中國在AI等領域的發展,但深度求索依然能構建出匹敵美國頂尖科技公司的AI模型。OpenAI前高管扎克·卡斯直言,美國的限制未能阻止DeepSeek的進步,「這凸顯了一個深刻的教訓:資源限制反而能激發創造力。」

AP圖片
數字新聞雜誌The Wire China發文稱,DeepSeek-R1的發佈將迫使懷疑論者重新評估中國的技術發展。深度求索對開源承諾的堅持也與OpenAI的專有策略形成鮮明對比,深度求索允許全球企業和開發者共同開發和改進技術,OpenAI則限制對其系統的訪問以維護競爭優勢。
該雜誌指出,美國決策者應該反思,通過設置障礙來確保領先地位的方法是否還行得通。美國的出口管制促使中國加速實現技術的自給自足,中美在芯片等領域的技術差距正逐漸縮小,美國的制裁雖然具有破壞性,卻可能反過來助推中國的創新能力。
文章寫道,美國的出口管制不僅削弱了美國科技公司的收入,也導致全球半導體供應鏈變得愈發「支離破碎」,「美國越是專注於遏制對手而不解決自身的缺陷,就越有可能加速其領先地位的喪失。」
深喉
** 博客文章文責自負,不代表本公司立場 **








